Handling File Uploads in a Serverless API Endpoint
Many types of applications allow users to upload files such as picture or video attachments to social media posts, profile photos to profiles, or documents to content management systems. File uploads are one of those things that can be really tricky to handle given your contraints. Those constraints may be API endpoint bandwidth, latency, or memory. Or maybe the infrastructure serving your API endpoint has a limited amount of time before it breaks the connection (ie. the 30 second AWS API Gateway timeout). In this post, I walkthrough how to support asynchronous file uploads in a serverless API endpoint.
Presigned URLs
A presigned URL is:
By default, all S3 objects are private. Only the object owner has permission to access them. However, the object owner can optionally share objects with others by creating a presigned URL, using their own security credentials, to grant time-limited permission to download the objects.
Amazon Web Services, Google Cloud Platform, Microsoft Azure, and DigitalOcean provide APIs allowing us to create presigned URLs programmatically.
Presigned URLs can also be used to permit a file upload to a protected location. We will use presigned URLs as a way to handle file uploads in this example. They enable us to handoff the file upload to our cloud provider. Our API endpoint persists any metadata related to the upload and generates a presigned URL for the upload. The client of our API will start an upload using the presigned URL and send the content directly to the cloud.
Architecture
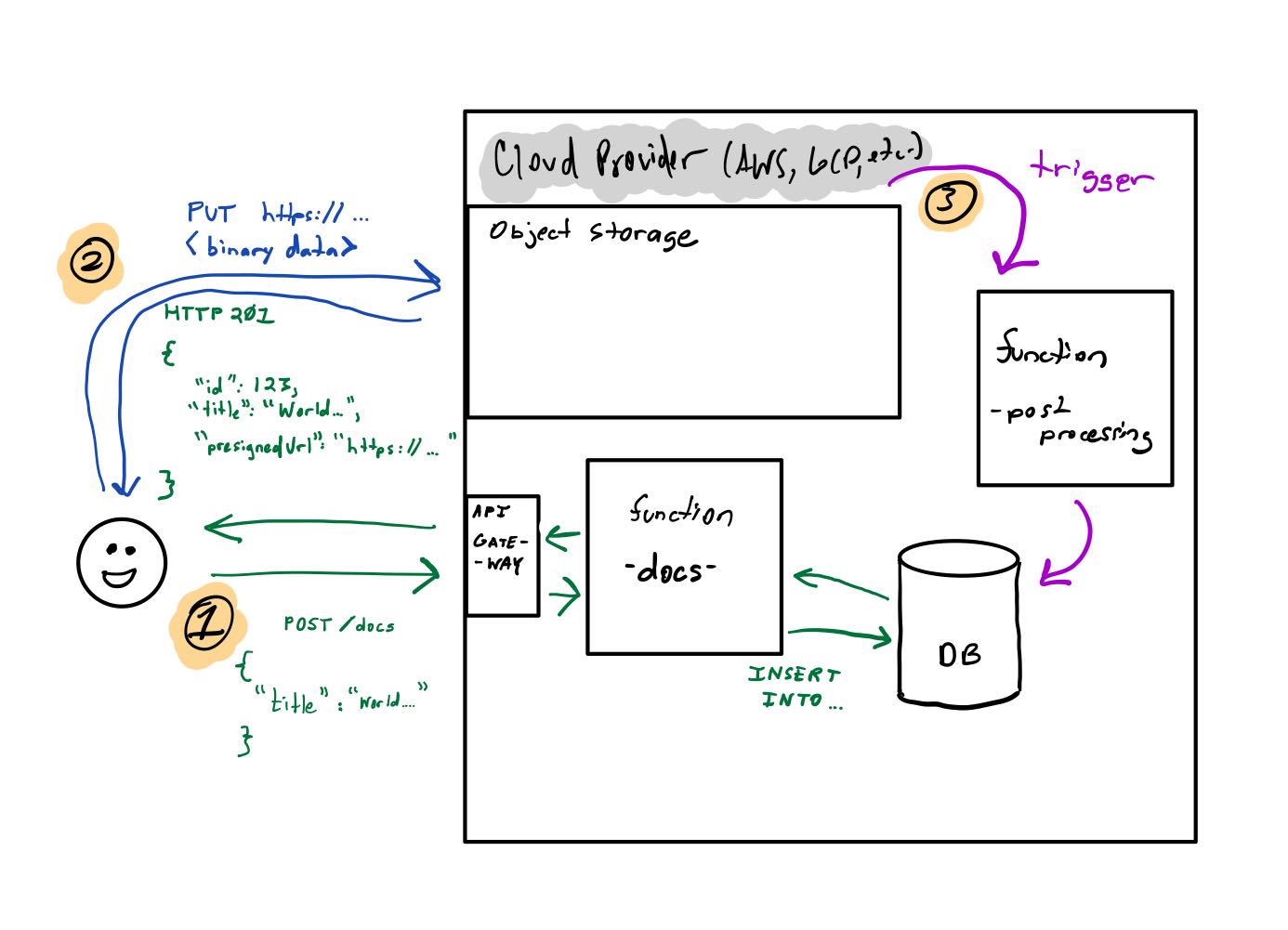
I’m building a webapp that allows users to create documents using an API endpoint, /doc. Clients call this endpoint:
POST /docs
{
"title": "World\'s greatest chocolate chip cookie recipe"
}
The POST body simple provides some metadata needed to create the document in the database. My API validates and processes this API call and responds with the created object and a presigned URL:
HTTP 201 Created
{
"id": "ds98sdkl",
"title": "World\'s greatest chocolate chip cookie recipe",
"createdAt": "2022-05-10",
"presignedUrl": "https://recipe-api-uploads.s3.amazonaws.com/ds98sdkl?AWSAccessKeyId=AKIA12345432523&Content-Type=text%2Fplain&Expires=1651873079&Signature=z7kYgMiJUCngrtCzmkHCsqGNv20%3D"
}
The client will execute an HTTP POST, sending the content of their file to the presigned URL. AWS will store the file at the designed bucket and key.
Finally, once the upload has been completed, another process will be executed that will do some post-processing and associate this bucket/key with the object stored in my database.
Code
My example won’t be a complete solution. Our API needs a database to store records. It needs infrastructure defined using Serverless, AWS SAM, TerraForm, or some other IaC (Infrastructure as Code) definition framework. The scope here will be a single API endpoint that leverages Nodejs and AWS to fullfil the API portion of our file upload.
const AWS = require('aws-sdk');
// assume dbService has a method to insert and retrieve a record
const dbService = require('../service/db-service');
AWS.config.update({ region: process.env.REGION });
async function create(event, context) {
const record = {
title: event.title
};
const id = await dbService.insert(record);
const createdDoc = await dbService.get(id);
const s3 = new AWS.S3();
const params = {
Bucket: 'recipe-api-uploads',
Key: id,
Expires: 300, // the url expires in 300 seconds / 5 minutes
ContentType: 'text/plain'
};
const presignedUrl = await s3.getSignedUrlPromise('putObject', params);
return {
...createdDoc,
presignedUrl: presignedUrl
};
}
export...
At its core, implementing this pattern is relatively simple. The client receives and parses the response, then executes an HTTP PUT similar to the example cURL call below.
curl --request PUT \
--url 'https://recipe-api-uploads.s3.amazonaws.com/ds98sdkl?AWSAccessKeyId=AKIA12345432523&Content-Type=text%2Fplain&Expires=1651873079&Signature=z7kYgMiJUCngrtCzmkHCsqGNv20%3D' \
--header 'Content-Type: application/octet-stream' \
--data LS0gLS0tLS0tLS0tLS0tLS0tL.....
Most (if not all) cloud providers allow developers to configure a notification that can trigger a process to handle post-processing on the uploaded content. For example, I would setup a AWS Lambda trigger on this S3 bucket. When the lambda is notified, it can then update the database record, pointing to this file and also do any post-processing.
Why
Why is this important? Beyond the technical contraints of being limited by bandwidth, memory, or time, it provides the client with some flexibility to respond to changing network conditions. For example, you can imagine a user posting a Tweet with a video attachment from their phone. The tweet gets posted and a second upload is triggered that can run in the background (and even pause and resume) allowing the user to continue on to the next thing.
Downsides
This pattern has it’s downsides. It adds complexity to the process of creating a document with an attachment. A simpler implementation is to execute the document creation and file upload as one atomic operation (API call). Therefore if one part of the operation fails (ie. the file upload0), we can end the operation or rollback the created record.
In the above example, what if the document gets posted, but the upload never finishes? What if the upload finished, but the database is never updated because of a network issue? As a developer, you need to take these scenarios under consideration and handle these failure modes.
🧇