My First Two Contributions to Open Source
I made my first two open source code contributions to other projects this month. I’ve put a bunch of my own creations into open source, but up until now, I’ve never contributed to other projects. It’s something that I’ve been striving to do since 2017. I’ve used open source libraries and frameworks to build software as a full-time software engineer and as part of my side projects. So I thought it was about time I give back. I’m 15 years into my software development career and have now made two contributions to other projects.
Getting Started
As I mentioned previously, I’ve used a lot of open source software over the course of my career. The more prominent examples being Android, Linux, Nodejs, Java, etc. Making a contribution to a major project seems somewhat daunting so I set my sights on projects that aren’t as big, but have been key to some software feature I’ve built or used. Enter StormCrawler.
About StormCrawler
StormCrawler is open source framework for using Apache Storm to do web crawling.
StormCrawler is an open source collection of resources for building low-latency, scalable web crawlers on Apache Storm. It is provided under Apache License and is written mostly in Java.
I implemented StormCrawler at my day job as a piece of a web archiving product. We already used Apache Storm for other distributed processing tasks, so implementing StormCrawler was straightforward.
Finding an Issue
I started out looking for issues to work on in the StormCrawler project. I found this one:
Enable extension parsing for SitemapParser #749
crawler-commons/crawler-commons#218 introduced support for sitemap extensions. These are not active by default and should be made configurable. The extension data found (if any) would be added to the outlink metadata and could therefore be used by a ParseFilter.
I’m really comfortable with the internals of Storm and StormCrawler so I ask a question. This question ends up being an important first step because it helps me open a line of communication with the maintainers.
My question:
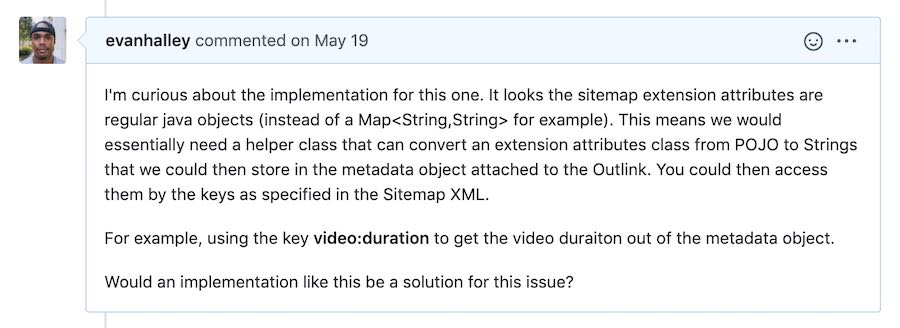
A pretty helpful response:
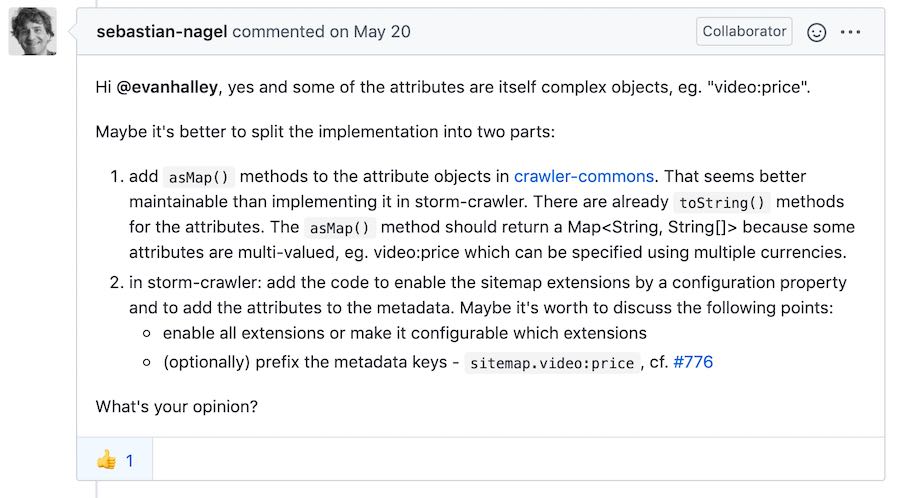
Now I have a very good idea of what I needed to do.
Making the Contribution
I intended on making my first open source contribution to StormCrawler, but I needed to do some work in crawler-commons first. Crawler-Commons is an open source library that is used by StormCrawler to parse XML sitemaps.
Crawler-Commons is a set of reusable Java components that implement functionality common to any web crawler. These components benefit from collaboration among various existing web crawler projects, and reduce duplication of effort.
I start my opening an issue.
ExtensionMetadata should be able to express itself as a Map #287
ExtensionMetadata objects should be expressable as a Map<String, String[]>. This has the benefit of making the data a little more portable for uses in other applications, like StormCrawler.
The originating request comes from StormCrawler/issue/749 with an implementation recommendation from @sebastian-nagel . Some implementation details.
Create an abstract method in ExtensionMetadata called public Map<String, String[]> asMap() Implement the method in classes extending ExtensionMetadata, return a Map<String, String[]> with all non-null attributes included.
Next I fork crawler-commons and create a branch for my work. At this point, its just a matter of me spending time to write the code and unit tests. The contribution isn’t that complex, its essentially writing methods that can serialize Sitemap ExtensionMetadata objects into Hashmaps. This process takes me a week or two. Just before I think it’s ready I open the pull request to have it merged into the project.
Adding asMap to ExtensionMetadata Interface #288
The feedback was pretty helpful.
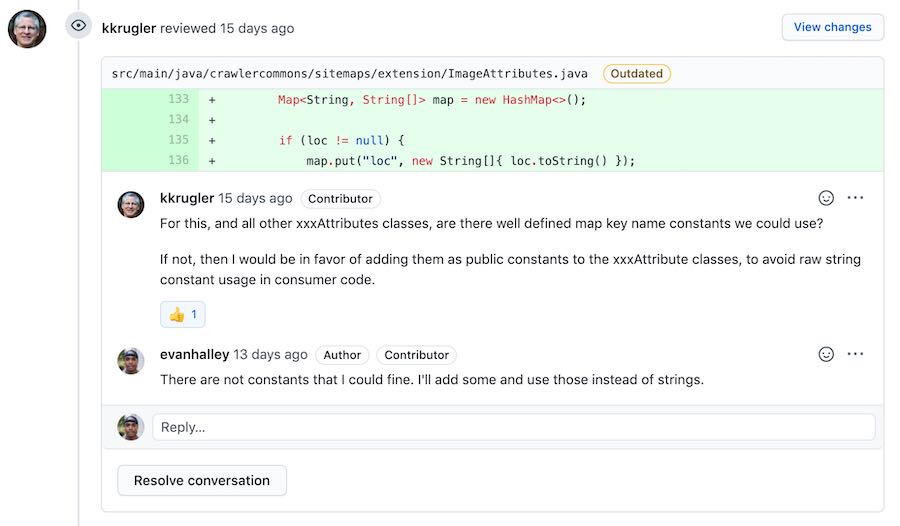
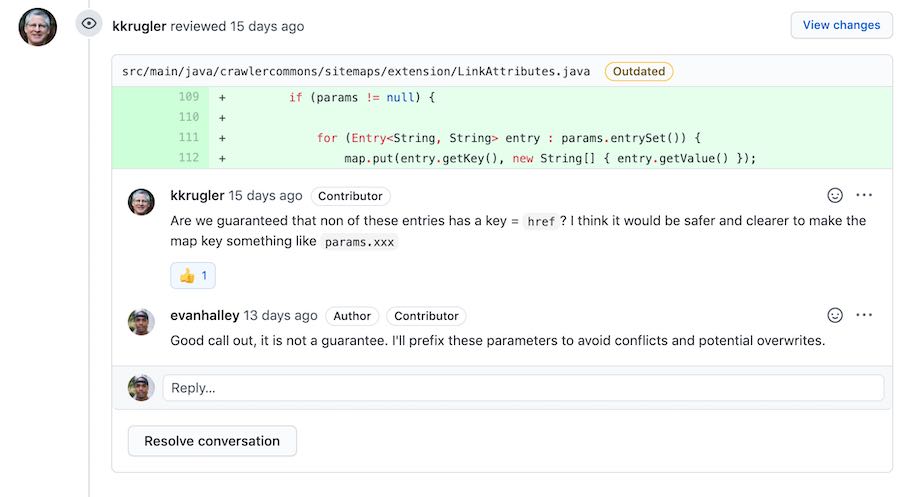
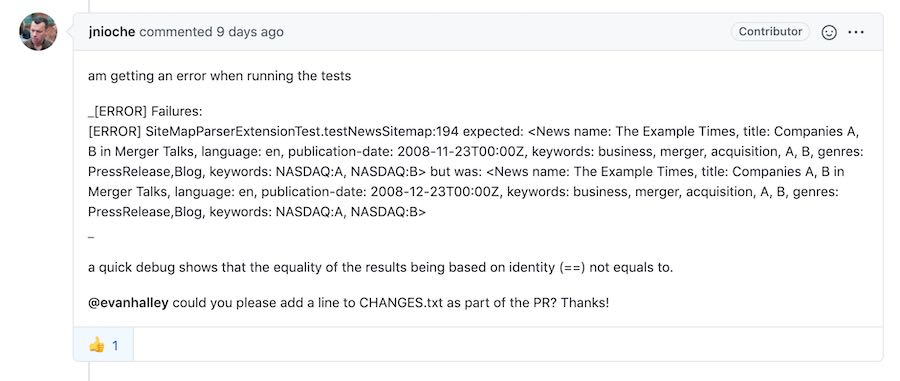
I actually ended up breaking a unit test by fixing a minor issue (which yielded my 2nd merged open source contribution).
After addressing the feedback, everything was good to go, the pull request got approved, and eventually merged.
Bonus
As I mentioned earlier, I broke a unit test by fixing a small bug in an objects .equals() method. Well, I wrote up a 2nd issue for the bug and fixed it in a separate pull request.
NewsAttribute.equals() compares the instance variable PublicationDate with itself. #289
NewsAttribute.equals compares the instance variable, PublicationDate, with itself.
It should be compared against the
that.publicationDate.
Fix for NewsAttribute.equals() compares the instance variable PublicationDate with itself. #291
My first two contributions ended up being merged into the open source project within a 24 hour period. It was exciting to go from 0 contributions to 2 in the span of a day.
The thing that I realized over this process was that contributing to open source is eerily similar to how I contribute code at my day job, which makes a ton of sense. There’s no reason, besides time, why I can’t make more contributions.
What’s Next
Now that I addressed part (1) of the feedback I got to my original question in the StormCrawler project, I’ll now be able to go back, implement the enhancement, and submit a pull request.
Happy Juneteenth!
🧇